Arun Mallya
Currently a Research Scientist at Meta (Gen AI → MSL) working on video generation, video editing models, and model auto-evaluation.
Previously a Senior Research Scientist in the Deep Imagination Research (DIR) group at NVIDIA (now Cosmos Lab). Part of the lab since its inception, when it began with just 3 members.
PhD from the University of Illinois at Urbana-Champaign, advised by Prof. Svetlana Lazebnik. MS in CS from UIUC; B.Tech in CSE from IIT Kharagpur.
My research currently focuses on generative content creation and their evaluation with vision-language models. I have previously dabbled in neural rendering and neural network efficiency, as well as probing their unexpected properties. My work on facial animation received the Best in Show award at the 2021 SIGGRAPH Real-time Live!, a showcase of cutting-edge, real-time technology demos.

Selected Research
See all on Google Scholar →Image/Video Generation

Facial Animation



Neural Rendering


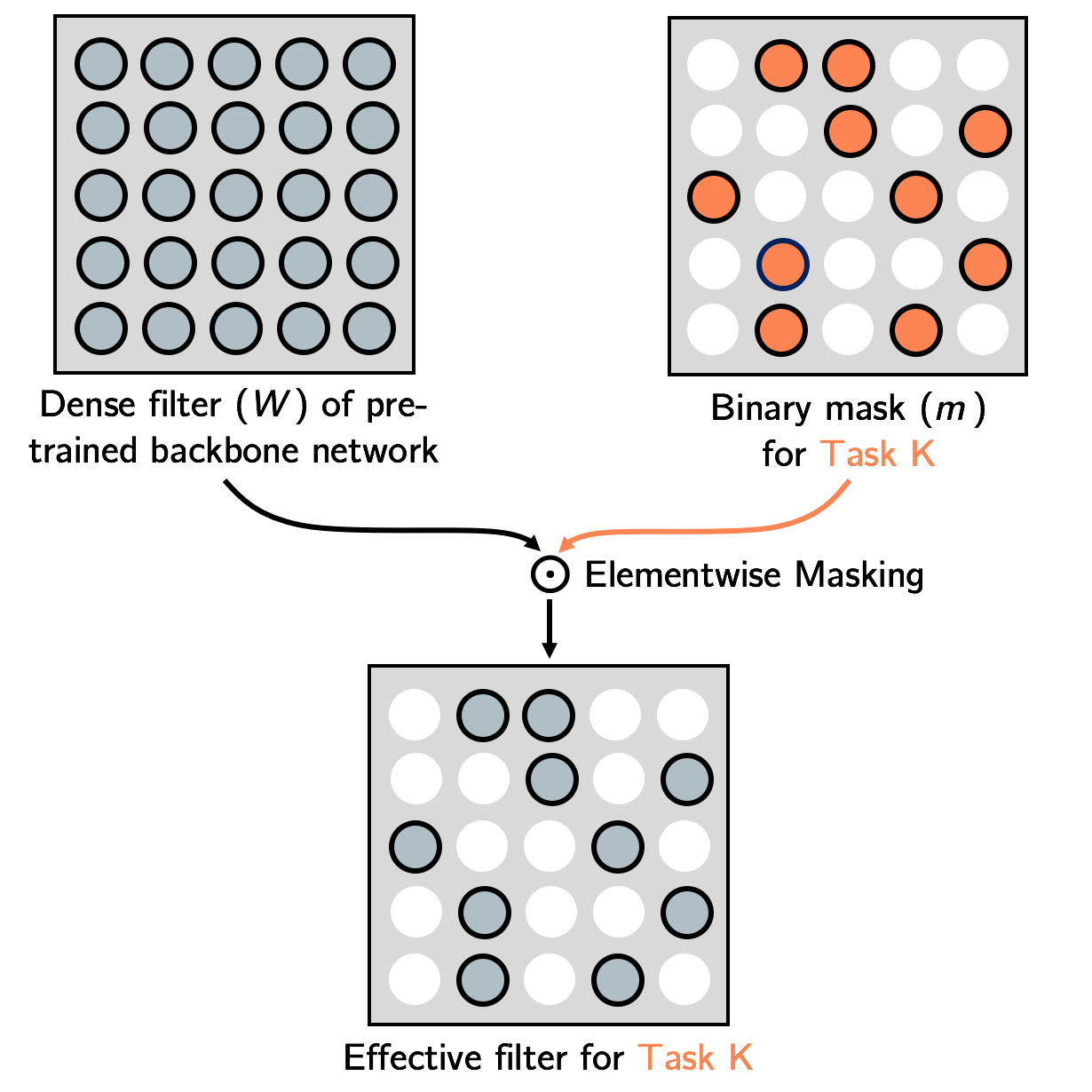
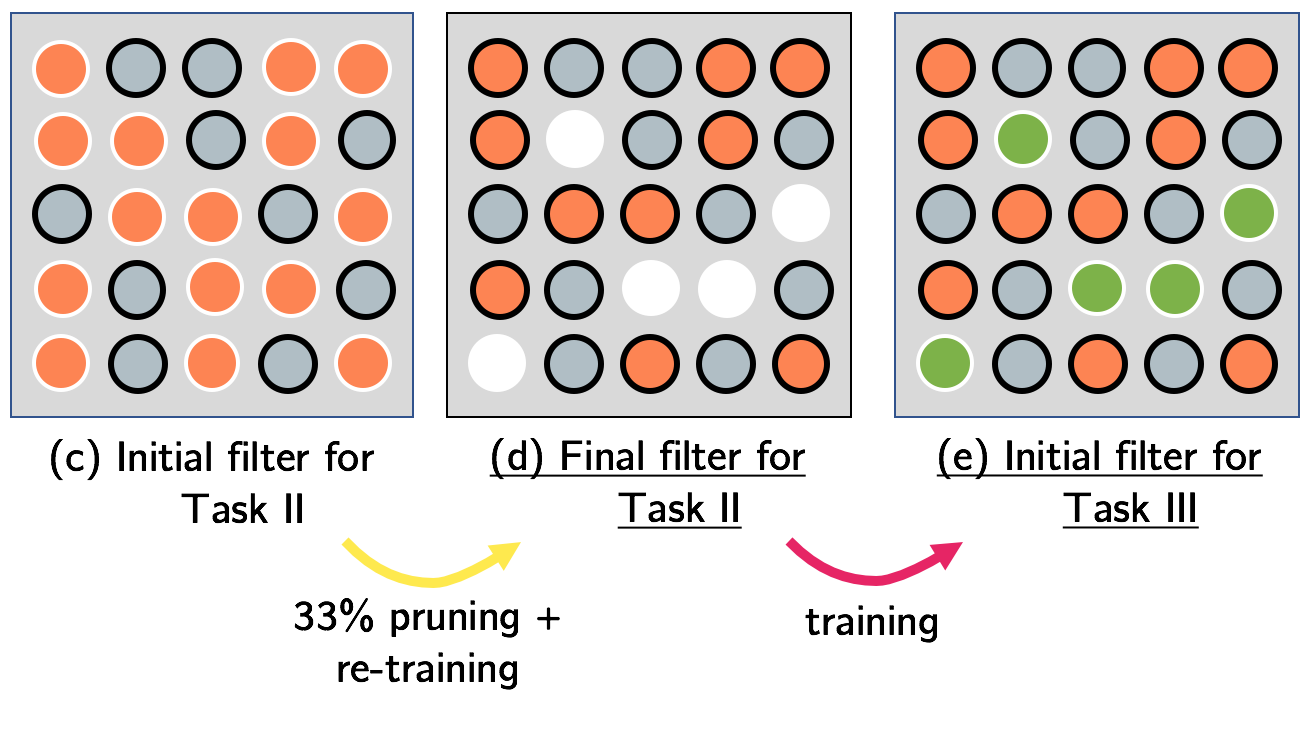
Model Efficiency / Interesting Properties


Tutorials & Workshops
Writeups & Notes
Hosted on GitHub. Edit requests, additions, and corrections are welcome.
- A Backpropagation Refresher
- An Illustrated Explanation of the LSTM Forward-Backward Pass
- Introduction to RNNs
- Introduction to RNNs — II
- Jupyter notebook to find Receptive Field Size and Effective Stride (supports dilated convs)
- Visualization of neuron connections and receptive field of a CNN (including dilation)